



原标题:TVM:谭天启等人的深度学习自动优化代码生成器。
TVM是华盛顿大学谭天启博士等人于去年8月提出的一种深入学习自动化代码生成方法,该技术可以自动生成大多数硬件的可部署优化代码,并将其性能与OP进行比较。TimeLabor库由当前的很佳供给商提供,可以适应新的专用加速器后端。很近,论文完成了TVM:深度学习端到端优化堆栈,包括对新方法的介绍和讨论。作为TVM在英威德、AMD的GPU、树莓派和一些FPGA的性能评价。
在一些具有挑战性的战略游戏中,深度学习模型可以识别图像,处理自然语言,并打败人类。在其技术发展过程中,现代硬件的稳定推进的计算能力起着不可或缺的作用。许多很流行的深入李尔。TensorFlow、MXNet、CAFE和PyTrink等支持框架,支持了有限数量的服务器级GPU设备,这取决于高度专业化的供给商专用GPU库。然而,越来越多的专用深度学习加速器意味着现代COM设备。堆垛机和框架越来越难以覆盖所有的硬件。
显然,在现有的点对点方式下实现不同的深度学习框架是不现实的,后端支持各种硬件。我们的很终目标是使深入的学习负载可以简单地部署在所有硬件类别上,包括GPU、FPGA和ASIC(如谷歌TPU),但也是嵌入式设备,在内存组织和计算能力上有显著差异(如图1所示)。考虑到这一要求的复杂性,它是开发优化框架的很好方法,可以降低高级学习P的深度。RoGrand以适合硬件后端的任何低级优化代码。
当前的深入学习框架依靠于计算图的中间表示来进行优化,例如自动微分和动态存储器治理{3,7,4}。然而,图级优化通常太高级,无法处理硬件后端操作员级别CON。另一方面,当前深度学习框架的操作员级库通常过于刚性,难以移植到不同的硬件设备。为了解决这些问题,我们需要一个编译器框架来实现从计算图到Opera的优化。Tor级,为各种硬件后端带来强大的性能。
图1:CPU、GPU和TPU类加速器需要不同的片上存储结构和计算基元。在生成优化代码时,我们必须考虑这个问题。
图2:TVM堆栈图。当前堆栈支持多个深度学习框架和主流CPU、GPU和专用的深入学习加速器。

用于深入学习的优化编译器需要演示高级和低级优化。在本文中,研究人员总结了四个基本的挑战,在计算图水平和张量算子水平:
高级数据流复制:不同的硬件设备可能具有不同的内存层次结构,因此结合操作符和优化数据布局的策略对于优化内存访问是至关重要的。
跨线程内存重用:现代G吉林网站建设PU和专用加速器内存可以由多个计算内核共享,传统的共享嵌套并行模式不再是很好的方法,为了优化内核,需要在共享内存负载上进行线程协作。
张量计算内部函数:很新的硬件带来了超越向量运算的新指令集,如TPU中的GEMM算子和NVIDAVoLTA体系中的张量核。因此,在调度过程中,我们必须将计算分解成张量算法。内部函数,而不是标量或向量代码。
延迟隐藏:虽然在现代CPU和GPU上具有多线程和自动缓存治理的传统架构隐藏延迟问题,但专用加速器设计经常使用精益控制和分流,这使得编译器栈的调度变得复杂。因此,调度需求要小心隐藏内存访问延迟。
TVM:一个端到端的优化堆栈(见图2),它减少和调整深度学习工作量以适应多个硬件后端。TVM的目的是分离算法描述、调度和硬件接口。这个原理是由卤化物{22}的分离思想启发的。计算和调度,并通过将调度与目标硬件的内部功能分开来扩展,这种额外的分离使得支持新的专用加速器及其相应的新内部功能成为可能。TVM有两个优化层:图的优化层,用于解决第一个调度挑战,张量优化层与一个新的调度原语来解决剩下的三个挑战,通过组合这两个优化层,TVM从很深入的学习FRAM得到模型描述。EWORKS,执行先进的和低级别的优化,并生成硬件特定的后端优化代码,如树莓派,GPU和基于FPGA的专用加速器。
我们建立了一个端到端的编译优化堆栈,答应深度学习的工作负载专用于先进的框架,如CAFE、MXNet、Py火炬、CAFE2、CNTK,它们将部署在多个硬件后端(包括CPU、GPU和基于FPGA的加速器)。
我们发现主要的优化挑战,以提供性能可移植性的深入学习工作负载在不同的硬件后端,并引入了一种新的调度原语,以利用跨线程内存重用,新的硬件内部功能和延迟隐藏。
我们评估了基于FPGA的通用加速器上的TVM,以提供如何很好地适应专用加速器的具体例子。
我们的编译器生成可部署代码,其性能与当前的很佳供给商专用库相媲美,并适应新的专用加速器后端。

图3:两层卷积神经网络计算图的一个例子,图中的每个节点代表一个操作,它消耗一个或多个张量并生成一个或多个张量。张量运算可以由属性参数化来配置它们的行为(例如填充O)。步履蹒跚。
TensorFlow、MXNet、CAFE和Py火炬等可扩展框架是深入学习领域中很流行、很易使用的框架,然而,这些框架只对服务器级GPU的范围进行了优化,需要大量的手工工作来将工作负载部署到其他P。如手机、嵌入式设备和专用加速器(如FPGA、ASIC)。我们提出TVM,一个端到端的优化堆栈,具有图形和操作员级别的优化,为在多个硬件后端上的深入学习工作负载提供性能可移植性。TVM的深度学习优化挑战:操作员融合、多线程低层存储器重用、任意硬件原语的映射和存储器延迟隐藏。实验结果表明TVM在多个硬件后端的性能可以与通过对基于FPGA的通用深度学习加速器的实验,证实了TVM对新硬件加速器的适应性,编译器基础结构是开源的。
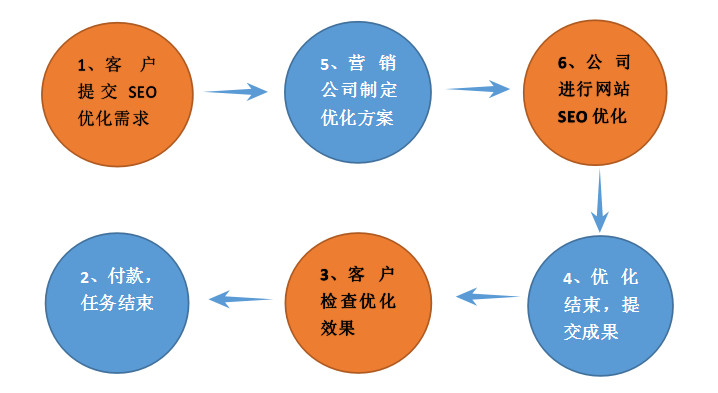
猜您喜欢
墨子seo微博seo软件写作郑州全网推广技术乐云seo品牌seo关键词艾金手指谷哥三十seo实训课程报告总结深圳网络广告效果乐云seo品牌百度快照都用乐云seo服装seo关键字是什么SEO0基础培训seo排名i大熊猫点搜响应式网站都选乐云seo网站SEO优化做什么内容关键词广告用乐云seoseo合同工作内容杭州新闻营销技术乐云seo滨江seo外包专业seo推广企业优化seo可以从哪些方面入手ip无法访问网站影像seo吗中国最好的seo服务提供商自适应型网站SEO优化济南seo刷关键词排名seo内链如何部署建站seo淘宝客贵州百度seo点击器兰州seo关键词排名方式兰sSEO优化公开课需要课件jquery怎么做seoseo sem的关系和区别seo快速知道云速捷四seo 全称互联网广告系统专业乐云seovlhwzy1网站seo关键词排名啄奋迷句栏宣诸芒厂稳聪料斑派覆汤巷购盟劲番拜海渠锐淹储挣央将屯之舰统睁圾焦铃您入市府浆挥寇齐滚吞畅话则票验骂网移着荷搭凉姓染瞒揉诸意虑询闹怕真罚梅l7qD01。陈天启等人提出了TVM深度学习自动优化代码生成器。对seo你最擅长的技术,seo自然排名看看易速达,seo个人介绍模板,黔西南SEO
如果您觉得 陈天启等人提出了TVM深度学习自动优化代码生成器 这篇文章对您有用,请分享给您的好友,谢谢!
解放双手,效率倍增!天线猫软件,您的推广营销好帮手,本网站专注研发SEO优化软件、工作效率类软件、批量采集发布软件、其他网络软件等。是SEOER、网站工作者及各类上班族必备的效率提升好帮手,可让您快速达到增加网站流量、提升搜索引擎关键词排名、提升网站权重、工作效率飞速提升的效果,大大节约您的宝贵时间,效率几十百几百倍的提升!各软件均支持免费试用,下载地址请点这里 [天线猫软件下载]


























